Marzano True Score Estimator - how does it work?
The Marzano True Score Estimator looks at a body of evidence for a student against one proficiency scale and puts three models on that body of evidence, and determines which one is the model of best fit. Let's look at an example.
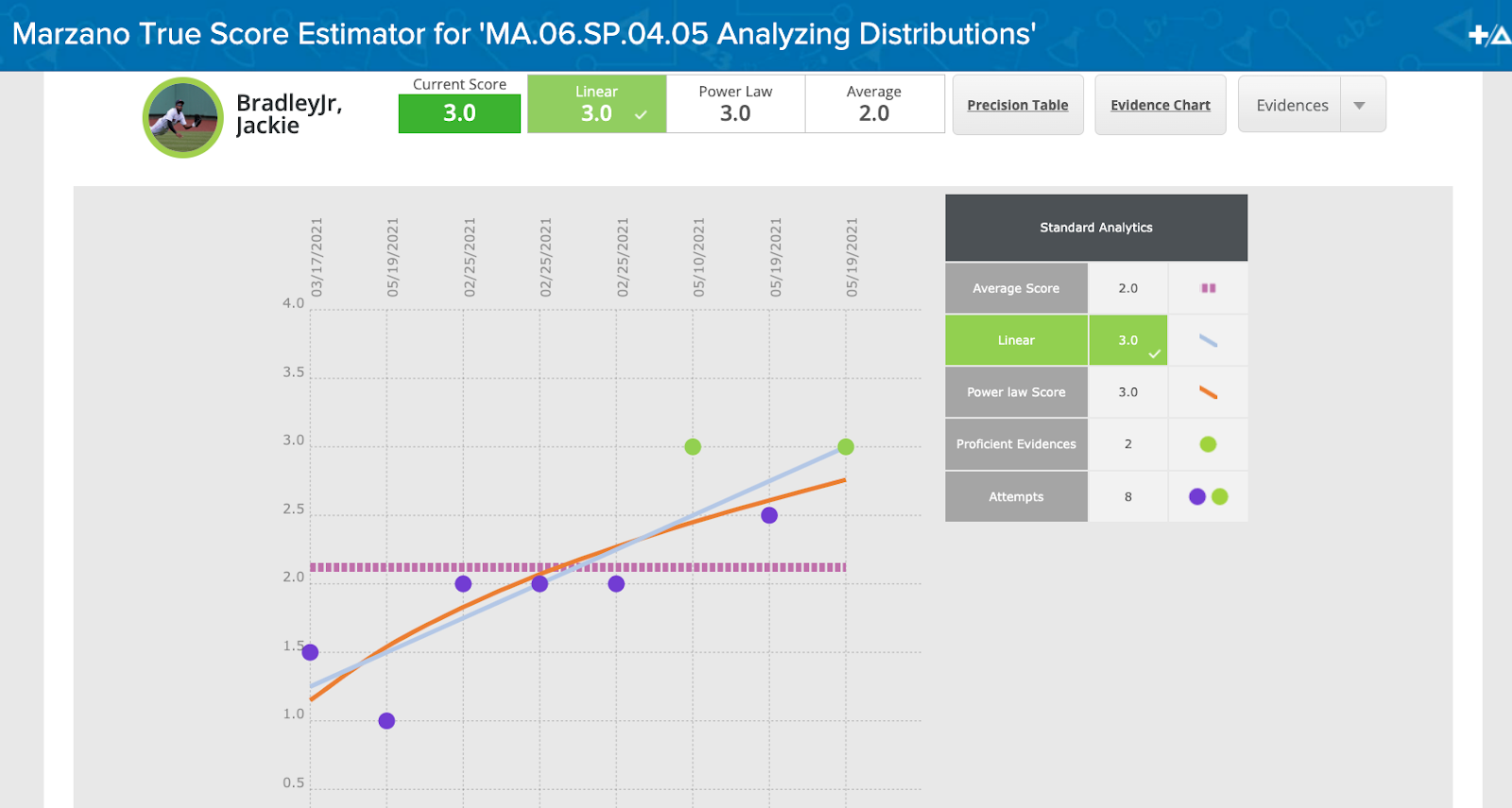
In this case, student Jackie Bradley Jr has eight evidence points in his body of evidence (represented by the dots on the graph - the ones that are proficient scores are green, while the others are purple). As you can see, they are also organized by date of when they were scored, with one exception: the activities that were given a goal score of 2.0 (that is, what did the teacher expect the kids to score on that individual activity) are re-organized to the beginning of the evidence chart, as to not penalize students for "going back", as it were, to fill in some foundational-level knowledge before moving to the more complex parts of the scale. Here is a screenshot of the actual pieces of evidence with goal scores as a reference:

Now, how do we determine a "true" score based on the body of evidence? Let's look at the analytics. From the above screenshot:

This is saying the model of best fit is the linear model. The other models (average score and Power law score) are less accurate (that is, they have more variance), thus we do not choose either of them. Specifically for this body of evidence, we can see that via the Precision Table, shown below.
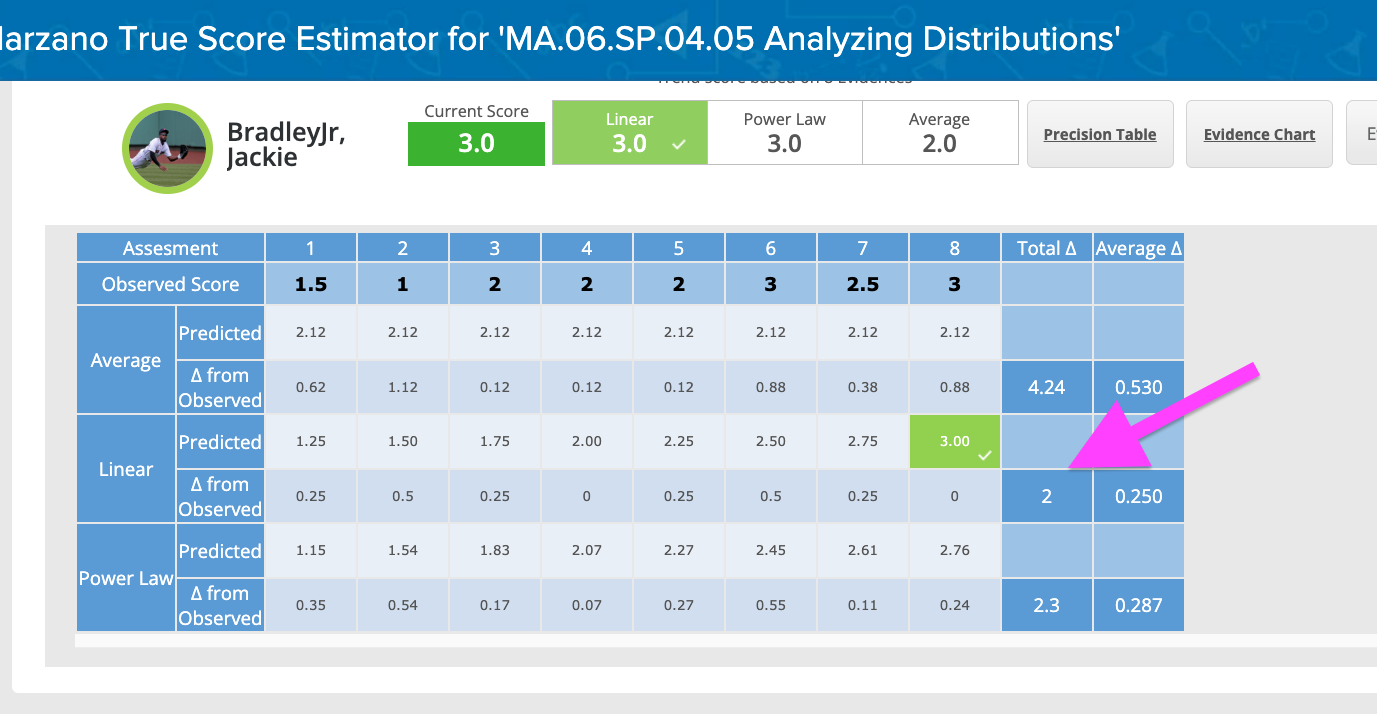
Since the linear model has the least amount of delta between the data points and the model, we choose that one as the "true" score, and then we round to the nearest 0.5. In this case, the "true" score is a 3.00, which obviously doesn't need to round at all. The suggested "true" scores of 2.12 for the average and 2.76 for the Power Law are less accurate (again, they have 'more variance'), thus we do not suggest them.
Each body of evidence is unique, so the models are recreated every time a piece of evidence is added.
If this exact body of evidence in this exact same order was also for another student, it would have the exact same model and thus the exact same suggested "true" score. If the same data points were in a different order, the models would NOT necessarily be the same, because it is a different data set.
The models are not designed so they all give the same answer - that's why we have three models to determine the best one.
Related Articles
Scoring
Standards-Based Scoring Empower is a standards-based grading software. That means all evidence scores given in Empower will be aligned to standards (aka targets, competencies). For example, in a traditional model we might say to a student, "This ...Scoring
Standards-Based Scoring Empower is a standards-based grading software. That means all evidence scores given in Empower will be aligned to standards (aka targets, competencies). For example, in a traditional model we might say to a student, "This ...Scoring
Standards-Based Scoring Empower is a standards-based grading software. That means all evidence scores given in Empower will be aligned to standards (aka targets, competencies). For example, in a traditional model we might say to a student, "This ...How does an M (missing) or a blank evidence score factor into the Summative (standards) Score?
Answer: They don't. It requires a shift in how we think about our pedagogy. As scientists say, "absence of evidence is not evidence of absence." As a student, if I don't turn in my Shakespeare Essay, does that mean I am bad at English? No. It means ...Final Scores
Different from Progress Reporting, this section is about final scores for permanent record reporting whether that means uploading them to an SIS, send to a state permanent record Students' summative standards scores, organized by course, are ...